Definition
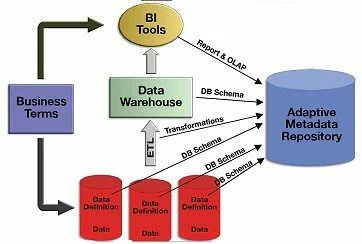
Metadata Repository is a centralized database which stored all the metadata (i.e schema) of all other system or database within an organisation. You can regard it as the library of metadata of metadata in an organisation
What Problem Pattern the Metadata Repository Solves
Duplicated Schema definition in different system
Imagine a scenario when an organisation has a CRM and eDM system which both have system properties First Name and Last Name , Middle Name and Gender . First of all, there will be a duplication time on defining the schema of the system properties (e.g. DataType , Validation Rules, Conditional Logic etc.). Besides, as the option values for Gender will also be the same (Male , Female, Unisex , Transgender), it will be spent duplicated time if we create the single dropdown list in the Gender field in both 2 systems.
If we can just define the concept (e.g. Gender) once and utitize as much as we want throught all the systems inside an organsiation, it will save lots of time.
Schema Definiton
But the point is , what if these 2 different systems are built by 2 different teams? How can they figure out the concept Gender is already defined by other teams in another system?
The Metadata Repository is acting as a metadata map to provide a bird view for the system developers and identify how to leverage the effort from other systems when they are building on their own.
Synonym and Word Variations in Schema Defintion
To reflect the intricacies of the real world, think about what if in the field Last Name in the CRM system is naming as Surnamein the eDM system, while in fact they are referring to the exactly same concept?
Duplicated records in different system.
To extend the example above, there will be different scenarios to record a new person in the CRM and eDM system, which means the maintenance cost will be increased as we are managing 2 sets of dataset which are overlapped and some are different.
How can we know that the person Elon Reeve Musk in the CRM is the same person as Elon Musk shown in the eDM due to the fact that the Middle Name is recorded in the CRM while there is no Middle Name field in the eDM system?
By using a Metadata Repository, the Relationships between these “Field” (i.e. Node) will be addressed and defined.
Functions of a Metadata Repository
As a Schema Template
In practical, it is the duty of the System Analyst to interview the client and address the business objects and its associated properties and pass them to the programmar to build the system.
For example, when building a lite version of a CRM , the System Analyst is expected to pass the following Schema Rules to the programmar:
First Name- Datatype = String
- UI = Single Text Field
- Max Length = 50 Characters
- Allow Duplicate = [Yes / No]
- UI = Toggle
- Placeholder Text = “Insert First Name”
- Default Value = NIL
- Index Key = [Yes / No]
- Datatype = String
Imagine you are working for a company which need to builds tens of different of Systems for hundreds of different of clients, each system may comprise hundreds of Business Objects, and each Business Object may have tens of Properties, and each of the properties has tens of Schema Rules, not to mention that the systems of each different client might have a slightly different versions of Properties and Schema Rules.
How can you , as a System Analyst, to pass the Schema Rules to the Programmar for coding will be time consuming process and big challenge.
A Metadata Repository is expected to store the metadata of all these different systems in 1 place as a template for future use, as well as speed up the communication among different parties
Metadata Harvesting
On the contrary, what if the client already had a in-house self-hosted and CRM up and running , and would like to build a eDM by leveraging the existing properties of the CRM?
Opposite to the function “As a Schema Template”, Metadata Harvesting is referring to collecting metadata from the existing system and turning them into the Schema Tempate.
Identify the Relationships among Properties of different Business Objects
After we have collected all the metadata from different data source, we have to find out the relationships among :
- Business Object (BO) to Business Object
- e.g. : 1 Client (BO) HAD_PURCHASED Many Product (BO)
- Business Object (BO) to Business Object Properties (BOP)
- e.g. : 1 Client (BO) HAS 1 Birthday Date (BOP)
- Properties (BOP) to Properties (BOP)
- e.g. : Last Name (BOP) in CRM IS_SAME as Surname (BOP) in eDM
Tools of Building Metadata
In order to speed up the development cycle of system building, following technology stacks are used to fulfill the objectives.
- Graph Database – to record the relationships among Business Objects (BO) and its Properties (BOP)
- API – to fetch the schema defintions from different systems.
- Graph Data Science (Python) Library – To evaluate or predict the relationships among Business Objects (BO) and its Properties (BOP)
- Graph Visualizer – to visualize the result in different prospective for different users.
- Semantic Search Bar – to semantically input the search terms in in the Graph Visualizer in order to cater any search problem including : infix search / prefix search / synonym / typo / partial search and etc.
Conclusion
Metadata Repository and Graph Database will be the game changer in any industry as it can scale up and speed up the Business Management System development cycle significantly.
Leave a Reply